本文共 6574 字,大约阅读时间需要 21 分钟。
1 np.split():
| Parameters: | ary : ndarray
indices_or_sections : int or 1-D array
axis : int, optional
|
|---|---|
| Returns: | sub-arrays : list of ndarrays
|
| Raises: | ValueError
|
例子:
1 当数据划分均等的时候:
>>> x = np.arange(9.0)
>>> np.split(x, 3) 输出:[array([ 0., 1., 2.]), array([ 3., 4., 5.]), array([ 6., 7., 8.])] >>> x = np.arange(8.0) >>> np.split(x, [3, 5, 6, 10]) 输出:[array([ 0., 1., 2.]), array([ 3., 4.]), array([ 5.]), array([ 6., 7.]), array([], dtype=float64)] 2 当数据划分不均等的时候,报错;import numpy as np
x = np.arange(7.0) print(np.split(x, 2))'array split does not result in an equal division')
ValueError: array split does not result in an equal division 此时使用 np.arry_split()>>> x = np.arange(8.0) >>> np.array_split(x, 3) [array([ 0., 1., 2.]), array([ 3., 4., 5.]), array([ 6., 7.])] >>> x = np.arange(7.0) >>> np.array_split(x, 3) [array([ 0., 1., 2.]), array([ 3., 4.]), array([ 5., 6.])]
成功。
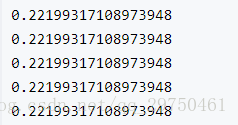
2 np.random.seed seed( ) 用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed( )值,则每次生成的随即数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。 如下测试:
from numpy import *
num=0
while(num<5):
random.seed(5)
print(random.random())
num+=1
结果:
再次修改以上代码:
from numpy import *
num=0
random.seed(5)
while(num<5):
print(random.random())
num+=1
结果:
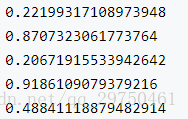
可以看出:random.seed(something)只能是一次有效。这个用的时候要注意。
3 np.meshgrid(x,y):
n [65]: xnums =np.arange(4)
In [66]: ynums =np.arange(5)
In [67]: xnums
Out[67]: array([0,1, 2, 3])
In [68]: ynums
Out[68]: array([0,1, 2, 3, 4])
In [69]: data_list= np.meshgrid(xnums,ynums)
In [70]: data_list
Out[70]:
[array([[0, 1, 2,3],
[0, 1, 2, 3],
[0, 1, 2, 3],
[0, 1, 2, 3],
[0, 1, 2, 3]]), array([[0, 0, 0, 0],
[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3],
[4, 4, 4, 4]])]
In [71]: x,y =data_list
In [72]: x.shape
Out[72]: (5L, 4L)
In [73]: y.shape
Out[73]: (5L, 4L)
In [74]: x
Out[74]:
array([[0, 1, 2,3],
[0, 1, 2, 3],
[0, 1, 2, 3],
[0, 1, 2, 3],
[0, 1, 2, 3]])
In [75]: y
Out[75]:
array([[0, 0, 0,0],
[1, 1, 1, 1],
[2, 2, 2, 2],
[3, 3, 3, 3],
[4, 4, 4, 4]])
由上面可以看出,meshgrid的作用是根据传入的两个一维数组参数生成两个数组元素的列表。如果第一个参数是xarray,维度是xdimesion,第二个参数是yarray,维度是ydimesion。那么生成的第一个二维数组是以xarray为行,ydimesion行的向量;而第二个二维数组是以yarray的转置为列,xdimesion列的向量。
4 nump中的为随机数产生器的seed():np.random.RandomState
nump.random.RandomState(0)为随机数产生器的种子,里面的数字相同,则产生的随机数相同。
rng = numpy.random.RandomState(23355)arrayA = rng.uniform(0,1,(2,3))
该段代码的目的是产生一个2行3列的assarray,其中的每个元素都是[0,1]区间的均匀分布的随机数
这里看以看到,有一个23355这个数字,其实,它是伪随机数产生器的种子,也就是“the starting point for a sequence of pseudorandom number”
对于某一个伪随机数发生器,只要该种子(seed)相同,产生的随机数序列就是相同的
1 numpy.random.seed()用于设置随机数种子
seed可以是一个int,满足0<=seed<=2(32−1),这个条件的int都可以做参数。 seed可以是一个array。 seed可以是None。 用一句话总结numpy.random.seed()和numpy.random.RandomState()的关系:相同处: 他们的参数都是随机数seed 不同处: numpy.random.RandomState()更为复杂,完全可以代替numpy.random.seed()这条语句。 随机数种子seed只有一次有效,在下一次调用产生随机数函数前没有设置seed,则还是产生随机数。
1.如果需要不产生随机数,则需要每次设置numpy.random.seed()。num=0while(num<5): np.random.seed(1) print(np.random.random()) num+=10.4170220047025740.4170220047025740.4170220047025740.4170220047025740.417022004702574
2.如果需要每次都产生随机数,则可以将随机数seed设置成None,或者不设置。
>>> import numpy >>>> numpy.random.RandomState(0).rand(4) >array([ 0.5488135 , 0.71518937, 0.60276338, 0.54488318]) >>> numpy.random.RandomState(0).rand(4) array([ 0.5488135 , 0.71518937, 0.60276338, 0.54488318]) >>> numpy.random.RandomState(0).rand(4) array([ 0.5488135 , 0.71518937, 0.60276338, 0.54488318]) >>> numpy.random.RandomState(None).rand(4) array([ 0.5488135 , 0.71518937, 0.60276338, 0.54488318]) >>> numpy.random.RandomState(None).rand(4) array([ 0.4236548 , 0.64589411, 0.43758721, 0.891773 ]) >>> numpy.random.RandomState(None).rand(4) array([ 0.96366276, 0.38344152, 0.79172504, 0.52889492])
5 np.mgrid函数
代码:
z = np.mgrid[1:5, 1:3]x, y = z[0], z[1]print(x)print(y)
结果:
[[1 1]
[2 2] [3 3] [4 4]] [[1 2] [1 2] [1 2][1 2]]
首先np.mgrid输出至少是一个三维的向量。
其中的元素,z[0],z[1]都是二维矩阵。
z[0]行数由np.mgrid第一个参数决定,上例为1:5,且为1 2 3 4,列数由1:3决定,利用广播机制填充。
z[1]列数由np.mgrid第二个参数决定,上例为1:3,且为1 2 ,行数由1:5决定,利用广播机制填充。
PS:z = np.mgrid[1:5:0.1, 1:3:0.1]
表示1:5切片间隔为0.1,1:3切片间隔为0.1
z = np.mgrid[1:5:4j, 1:3:3j]
表示1:5切片均匀取数,取4个,1:3切片均匀取数,取3个
6 np 形成矩阵
ndarray提供了一些创建二维数组的特殊函数。numpy中matrix是对二维数组ndarray进行了封装之后的子类。这里介绍的关于二维数组的创建,返回的依旧是一个ndarray对象,而不是matrix子类。关于matrix的创建和操作,待后续笔记详细描述。为了表述方便,下面依旧使用矩阵这一次来表示创建的二维数组。
diag函数返回一个矩阵的对角线元素、或者创建一个对角阵,对角线由参数k控制 2. diagflat函数以输入作为对角线元素,创建一个矩阵,对角线由参数k控制 3. tri函数生成一个矩阵,在某对角线以下元素全为1,其余全为0,对角线由参数k控制 4. tril函数输入一个矩阵,返回该矩阵的下三角矩阵,下三角的边界对角线由参数k控制 5. triu函数与tril类似,返回的是矩阵的上三角矩阵 6. vander函数输入一个一维数组,返回一个范德蒙德矩阵 7 eye 形成一个单位矩阵
#diag用法>>> x = np.arange(9).reshape((3,3))>>> xarray([[0, 1, 2], [3, 4, 5], [6, 7, 8]])>>> np.diag(x)array([0, 4, 8])>>> np.diag(x, k=1)array([1, 5])>>> np.diag(x, k=-1)array([3, 7])>>> np.diag(np.diag(x))array([[0, 0, 0], [0, 4, 0], [0, 0, 8]])>>> np.diag(np.diag(x), k=1)array([[0, 0, 0, 0], [0, 0, 4, 0], [0, 0, 0, 8], [0, 0, 0, 0]])#diagflat用法>>> np.diagflat([[1,2],[3,4]])array([[1, 0, 0, 0], [0, 2, 0, 0], [0, 0, 3, 0], [0, 0, 0, 4]])>>> np.diagflat([1,2,3], k=-1)array([[0, 0, 0, 0], [1, 0, 0, 0], [0, 2, 0, 0], [0, 0, 3, 0]])#tri>>> np.tri(3,4, k=1, dtype=int) array([[1, 1, 0, 0], [1, 1, 1, 0], [1, 1, 1, 1]])>>> np.tri(3,4)array([[ 1., 0., 0., 0.], [ 1., 1., 0., 0.], [ 1., 1., 1., 0.]])#tril与triu>>> x = np.arange(12).reshape((3,4))>>> xarray([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]])>>> np.tril(x, k=1) array([[ 0, 1, 0, 0], [ 4, 5, 6, 0], [ 8, 9, 10, 11]])>>> np.triu(x, k=1) array([[ 0, 1, 2, 3], [ 0, 0, 6, 7], [ 0, 0, 0, 11]])#vander>>> np.vander([2,3,4,5])array([[ 8, 4, 2, 1], [ 27, 9, 3, 1], [ 64, 16, 4, 1], [125, 25, 5, 1]])>>> np.vander([2,3,4,5], N=3)array([[ 4, 2, 1], [ 9, 3, 1], [16, 4, 1], [25, 5, 1]])